Random Fourier Features for Kernel Density Estimation
The NIPS paper Random Fourier Features for Large-scale Kernel Machines, by Rahimi and Recht presents a method for randomized feature mapping where dot products in the transformed feature space approximate (a certain class of) positive definite (p.d.) kernels in the original space.
We know that for any p.d. kernel there exists a deterministic map that has the aforementioned property but it may be infinite dimensional. The paper presents results indicating that with the randomized map we can get away with only a “small” number of features (at least for a classification setting).
Before applying the method to density estimation let us review the relevant section of the paper briefly.
Bochner’s Theorem and Random Fourier Features
Assume that we have data in 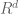



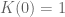
The theorem by Bochner states that under the above conditions 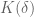

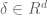


where (1) is because 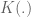

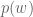


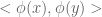
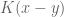
Therefore, for 

with 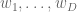
Gaussian RBF Kernel
The Gaussian radial basis function kernel satisfies all the above conditions and we know that the Fourier transform of the Gaussian is another Gaussian (with the reciprocal variance). Therefore for “linearizing” the Gaussian r.b.f. kernel, we draw 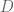
Parzen Window Density Estimation
Given a data set 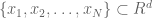
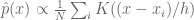
where 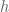
A common kernel that is used for Parzen window density estimation is the Gaussian density. If we make the same choice we can apply our feature transformation to linearize the procedure. We have

where
Therefore all we need to do is take the mean of the transformed data points and estimate the pdf at a new point to be (proportional to) the inner product its transformed feature vector with the mean.
Of course since the kernel value is only approximated by the inner product of the random Fourier features we expect that the estimate pdf will differ from a plain unadorned Parzen window estimate. But different how?
Experiments
Below are some pictures showing how the method performs on some synthetic data. I generated a few dozen points from a mixture of Gaussians and plotted contours of the estimated pdf for the region around the points. I did this for several choices of 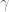
First let us check that the method performs as expected for large values of 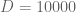

D = 10000 and gamma = 2.0

D = 10000 and gamma = 1.0

D = 10000 and gamma = 0.5
—————————————————————————
—————————————————————————
Now let us see what happens when we decrease 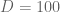

D=1000 and gamma = 1.0

D=100 and gamma = 1.0
—————————————————————————
—————————————————————————
The following picture for 
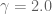

D = 1000 and gamma = 2.0
—————————————————————————
—————————————————————————
Discussion
It seems that even for a simple 2D example, we seem to need to compute a very large number of random Fourier features to make the estimated pdf accurate. (For this small example this is very wasteful, since a plain Parzen window estimate would require less memory and computation.)
However, the pictures do indicate that if the approach is to be used for outlier detection (aka novelty detection) from a given data set, we might be able get away with much smaller

{kind=link}
Thank you. I was having some trouble understanding this paper
Thanks a lot it really helps to understand the paper.
thanks a lot. IT would have been great if you can share the code.
Thanks a lot. It was really easy to understand. Can you please upload your codes too.
Thanks